
Best C# OCR libraries: 2025 Updated Guide

If you’re looking for “the best C# OCR Library”, we’ve provided below a detailed breakdown to help you make a good decision.
Businesses process more than 2.5 trillion PDF documents every year. With so much digital content, text recognition capabilities are critical for modern applications. The C# text recognition library you choose can dramatically impact processing speed, accuracy, and system resource usage.
C# libraries offering OCR (Optical Character Recognition) show significant differences in performance. Document complexity, image quality, and the need for batch or real-time processing all play major roles. In some benchmarks, performance varied by as much as 300% between libraries—making your choice more than a technical decision; it’s a strategic one.
In this in-depth technical benchmark, we evaluate top C# text recognition libraries by measuring their speed, accuracy, resource consumption, and suitability for real-world scenarios.
What We’ve Covered
- How OCR engines perform across document types
- Which libraries balance speed and accuracy best
- Technical factors to consider for your specific use case
- How to implement and optimize OCR in your C# applications
Understanding text recognition technologies
Modern OCR systems are built on a range of recognition techniques. Knowing the difference between OCR, ICR, and OMR helps you select the right tool for your needs.
OCR vs. ICR vs. OMR
| Technology | Purpose | Use Case |
|---|---|---|
| OCR (Optical Character Recognition) | Recognizes printed or typed text from images | PDFs, scanned documents, receipts |
| ICR (Intelligent Character Recognition) | Detects handwritten text, especially numeric | Forms, handwriting fields |
| OMR (Optical Mark Recognition) | Detects checkmarks or filled areas | Surveys, exams, ballots |
You’ll also encounter specialized tools like:
Machine Learning in Modern C# OCR Library Engines
Today’s top OCR libraries for C# rely on machine learning and deep learning techniques, including:
- Adaptive Document Learning: Models adapt over time to document types
- Neural Networks: Handle varied fonts, styles, and scan quality
- NLP (Natural Language Processing): Improves accuracy using context-aware corrections
Most C# OCR libraries now support:
- 100+ languages
- Unicode and RTL scripts
- Multi-threaded processing
- PDF, TIFF, PNG, and other formats
Compatibility Considerations for C# Developers
When selecting an OCR library for .NET, consider:
- ✅ Threading Model: Look for thread-safe APIs and native multi-threading
- ✅ Framework Independence: Avoid libraries that depend on external software (e.g., MS Word)
- ✅ Desktop & Web Support: Must integrate cleanly with WinForms, WPF, or REST APIs
- ✅ Clean API Design: Ensure support for both C# and VB.NET
Your application type (desktop vs. cloud) will influence integration and performance.
Performance and Benchmarking
We benchmarked major C# OCR libraries using:
- Standard document types: Single-page scans, multipage TIFFs, handwritten forms
- UNLV dataset: Clean and degraded samples
- Performance metrics: Speed, accuracy, memory usage, CPU load
🕒 Speed benchmark: Characters per second
| Library | Characters/Second | Relative Speed |
|---|---|---|
| GdPicture.NET | 12,500+ | 100% (baseline) |
| ABBYY | 11,700 | 94% |
| Tesseract | 9,200 | 74% |
| Windows OCR | 7,800 | 62% |
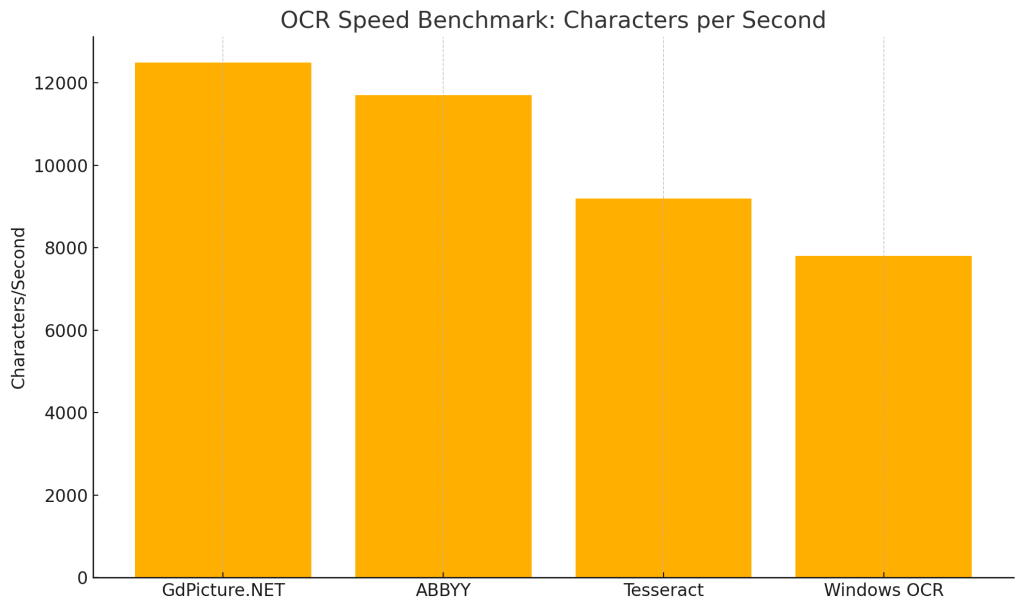
GdPicture.NET showed top-tier speed, especially with multi-page TIFF documents. Simpler documents showed smaller differences between engines.
🎯 Accuracy (UNLV dataset results)
The University of Nevada Las Vegas (UNLV) dataset remains a widely used benchmark for evaluating OCR accuracy. In our tests, clean documents yielded 94–98% accuracy, while degraded samples dropped to 75–89%, depending on the engine and preprocessing.
For numeric handwriting, ICR-capable libraries outperformed standard OCR by up to 35%, especially in structured forms with boxed input fields.
🧠 Memory and CPU usage
| Library | RAM Usage | CPU Load |
|---|---|---|
| GdPicture.NET | 200–450MB | 70–90% (multi-core) |
| Tesseract | 120–200MB | Single-threaded |
| ABBYY | ~350MB | Multi-threaded |
| Windows OCR | 150–300MB | Moderate |
Multi-threaded engines significantly outperform in batch environments.
Multi-Threading in C# applications
Native thread-safe APIs enable 2.5x–3.8x speedups on multi-core systems. Batch and real-time applications both benefit when libraries handle threading internally, avoiding manual thread management.
C# integration: Example using GdPicture.NET
GdPicture.NET OCR SDK makes it simple to implement common text recognition tasks. Here’s a simple implementation that creates a searchable PDF from a scanned document:
// Import GdPicture namespaces
using GdPicture14;
var ocr = new GdPictureOcr();
ocr.ResourceFolder = @"C:\OCR\Resources";
ocr.EnableOrientationDetection = true;
// Load and process image
var gdPictureImaging = new GdPictureImaging();
int imageID = gdPictureImaging.CreateGdPictureImageFromFile(@"C:\input.tiff");
ocr.SetImage(imageID);
ocr.Recognize();
// Output searchable PDF
int pdfID = ocr.GetPDFOutput();
var gdPicturePDF = new GdPicturePDF();
gdPicturePDF.SaveToFile(pdfID, @"C:\output_searchable.pdf");
To extract text from a specific region:
ocr.SetRect(100, 200, 400, 100); // Define rectangular zone
ocr.Recognize();
string zoneText = ocr.GetText();
Error handling & preprocessing
Strong OCR implementations need proper exception handling because recognition processes can fail at multiple points:
- Input validation through try-catch blocks around file operations
- Recognition quality checks via confidence values
- Resource cleanup in finally blocks to prevent memory leaks
Pre-Processing techniques for improved recognition
Several pre-processing steps can improve accuracy before image recognition:
- Deskewing – Correct document orientation
- Noise removal – Filter out speckles and artifacts
- Contrast enhancement – Improve text-background separation
- Binarization – Convert to black and white for clearer character edges
Professional libraries include built-in pre-processing features. Custom preparation often works better for specialized documents. These techniques can improve recognition accuracy by 15-30% based on document quality.
TL;DR: You can implement text recognition in C# by choosing a high-performance library like GdPicture.NET, handling errors properly, and using pre-processing techniques to get the best accuracy.
Choosing the Right C# OCR Library: Use Case Guide
| Use Case | Recommended Features | Best Fit |
|---|---|---|
| Enterprise document processing | Batch OCR, PDF/A output, multi-threading | GdPicture.NET, ABBYY |
| Mobile & embedded apps | Low RAM usage, adjustable recognition modes | Tesseract, Windows OCR |
| Handwriting recognition | ICR, numeric box detection | GdPicture.NET (ICR) |
| Mixed barcode + text | OCR + QR/DataMatrix support in one API | GdPicture.NET |
| Real-time applications | Zonal OCR, multi-page processing | GdPicture.NET, ABBYY |
TL;DR
- GdPicture.NET leads with 12,500+ characters/sec and up to 98% accuracy on clean docs
- Multi-threading improves performance by 2.5x–3.8x
- Preprocessing boosts OCR accuracy 15–30%
- Use thread-safe APIs to avoid concurrency issues in production
📊 Quick Comparison Table for Common C# OCR Libraries
| Library | Speed | Accuracy | ICR Support | Multi-threaded | Best For |
|---|---|---|---|---|---|
| GdPicture.NET | ★★★★★ | ★★★★★ | ✅ | ✅ | Enterprise, mixed docs |
| ABBYY | ★★★★☆ | ★★★★★ | Partial | ✅ | Legal, financial workflows |
| Tesseract | ★★★☆☆ | ★★★★☆ | Limited | ❌ | Open-source projects |
| Windows OCR | ★★☆☆☆ | ★★★☆☆ | ❌ | ❌ | Lightweight desktop tools |
FAQs for C# OCR Library
1. What is the best C# text recognition library for enterprise applications?
GdPicture.NET stands out as a top performer for enterprise-scale document processing. It offers superior speed and accuracy, processing over 12,500 characters per second with 94-98% accuracy on clean documents. Its multi-threading support and ability to handle 100+ document formats make it ideal for high-volume enterprise environments.
2. How can I improve OCR accuracy in my C# application?
To enhance OCR accuracy, implement pre-processing techniques such as deskewing, noise removal, contrast enhancement, and binarization. These methods can increase recognition accuracy by 15-30% depending on document quality. Additionally, choose a library with adaptive document learning and context-aware correction features.
3. What factors should I consider when selecting a text recognition library for mobile applications?
For mobile applications, prioritize libraries with a small memory footprint and configurable recognition parameters. Look for lightweight OCR implementations that balance reasonable accuracy with minimal resource consumption, allowing you to adjust the speed-accuracy tradeoff based on available device resources.
4. Can C# text recognition libraries handle handwritten text?
Most C# libraries offer limited handwriting support, primarily for numeric characters in defined boxes. If your application requires handwriting recognition, look for libraries with Intelligent Character Recognition (ICR) capabilities. However, be aware that full cursive text recognition is still an evolving technology in most C# libraries.
5. How can I optimize text recognition for real-time applications in C#?
For real-time text recognition, focus on processing speed by implementing zone-specific recognition, which targets only relevant document areas. Choose libraries that support region-specific processing and implement parallel recognition workflows for multi-page documents. Additionally, utilize multi-threading capabilities to maximize throughput on multi-core systems.
Final Thoughts
Your choice of a C# OCR library can shape your application’s entire document pipeline—from accuracy and performance to future scalability. Our benchmark highlights GdPicture.NET as the most capable all-around OCR solution in 2025, especially for enterprise and performance-critical applications.
If you’d like to test it yourself, most of these libraries offer free trials and public SDKs for evaluation. Make sure your final pick aligns not just with current needs—but also your roadmap for the next few years.

Hulya is a frontend web developer and technical writer at GDPicture who enjoys creating responsive, scalable, and maintainable web experiences. She’s passionate about open source, web accessibility, cybersecurity privacy, and blockchain.
Tags: